Analyse de Sentiments - Amazon Reviews
AcadémiquePipeline de Data Science complet : NLP avec Spacy, classification (KNN, Random Forest) et régression linéaire pour prédire la satisfaction client.
Contexte du Projet
Réalisé dans le cadre de la SAE S5 “Analyse automatique de données”, ce projet a pour but d’exploiter un jeu de données réel (Amazon Reviews 2023 - Software) pour effectuer des tâches de classification et de régression.
L’objectif est de prédire la note (1 à 5 étoiles) attribuée par un utilisateur uniquement à partir du texte de son commentaire.
Pipeline Technique
Nous avons développé une chaîne de traitement complète pour transformer du texte brut en prédictions exploitables.
1. Préparation et NLP
- Nettoyage : Traitement du langage naturel avec spaCy (tokenization, suppression des stop-words).
- Vectorisation : Transformation des commentaires en données numériques.
- Rééquilibrage : Application d’un Stratified Undersampling (via
imbalanced-learn) pour corriger la surreprésentation des avis positifs et éviter le biais du modèle. - Normalisation : Utilisation de
StandardScalerpour mettre à l’échelle les features.
2. Modèles de Classification
Nous avons entraîné et comparé plusieurs algorithmes pour classifier les avis (positifs vs négatifs, ou multi-classes) :
- K-Nearest Neighbors (KNN)
- Arbre de Décision (Decision Tree)
- Random Forest (Modèle retenu pour ses meilleures performances)
- Fine-tuning : Recherche des meilleurs hyperparamètres via
GridSearchCVintégré dans des Pipelines Scikit-learn. - Comparaison : Graphiques à barres comparant le F1-Score Macro pour identifier la meilleure configuration texte/modèle.
3. Optimisation et Régression
- Régression Linéaire : Tentative de prédiction du score exact (RMSE) en se basant sur des indicateurs textuels.
- Analyse des Résidus : Utilisation de graphiques de dispersion (Scatter Plots) et d’histogrammes pour analyser l’erreur de prédiction (Note réelle vs Prédite).
- Performance : Évaluation via le RMSE sur les données de test et de validation pour mesurer la précision numérique du modèle.
Visualisation des Résultats
Pour évaluer la pertinence de nos modèles, nous avons généré :
- F1-Score : Pour mesurer l’équilibre entre précision et rappel sur chaque catégorie de note.
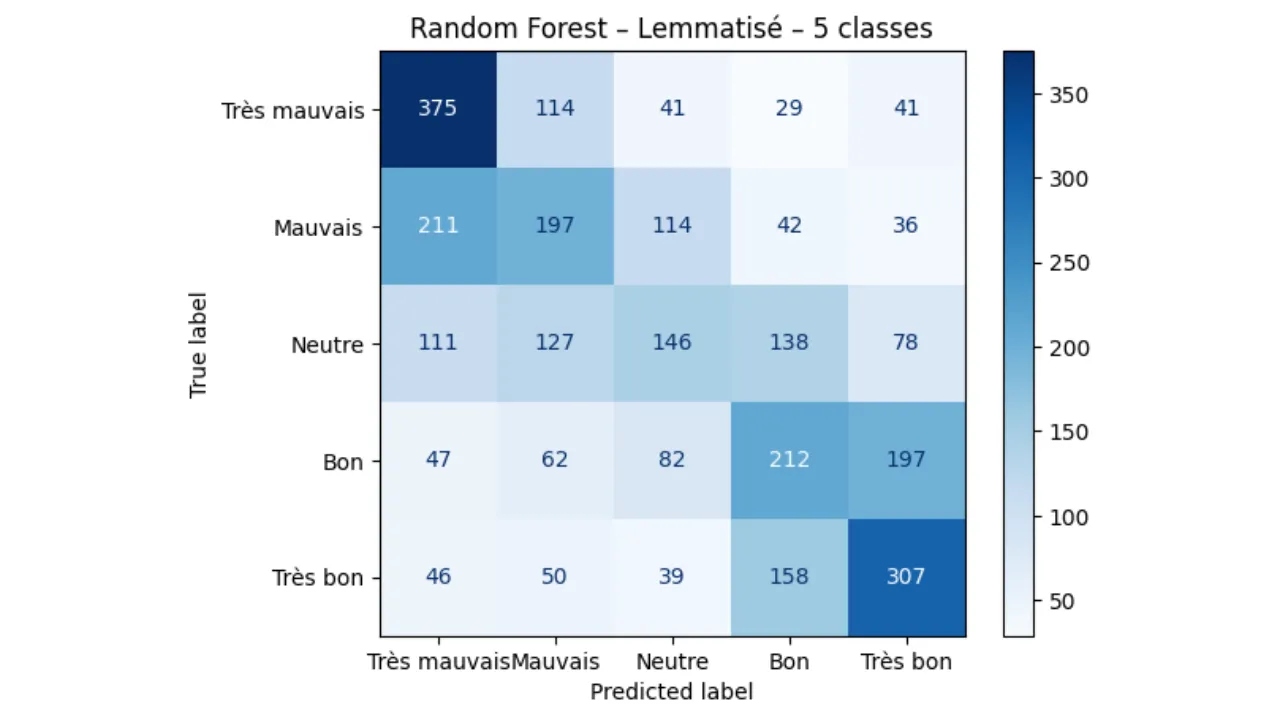
- Matrices de Confusion pour analyser les erreurs de classification.
- Courbes Précision-Rappel pour vérifier la robustesse face au déséquilibre des classes.
- Histogrammes des résidus pour valider la normalité des erreurs en régression.
- Comparaison de RMSE entre les différentes méthodes de prétraitement (RAW vs LEMMA).