Projects
Amazon Reviews NLP Analysis
AcademicA complete Data Science pipeline: NLP with Spacy, classification (KNN, Random Forest), and linear regression to predict customer satisfaction.
Project Context
Developed during the “Automatic Data Analysis” course (SAE S5), this project leverages a real-world dataset (Amazon Reviews 2023 - Software) to perform classification and regression tasks.
The goal is to predict a user’s rating (1 to 5 stars) based solely on the text of their review.
Technical Pipeline
We built a comprehensive pipeline to transform raw text into actionable predictions.
1. Data Preparation & NLP
- Cleaning: Natural Language Processing using spaCy (tokenization, stop-word removal).
- Vectorization: Converting text comments into numerical data.
- Rebalancing: Applied Stratified Undersampling (via
imbalanced-learn) to address the dataset’s heavy bias towards positive reviews. - Normalization: Used
StandardScalerto scale features appropriately.
2. Classification Models
We trained and compared several algorithms to classify reviews (positive vs. negative, or multi-class):
- K-Nearest Neighbors (KNN)
- Decision Tree
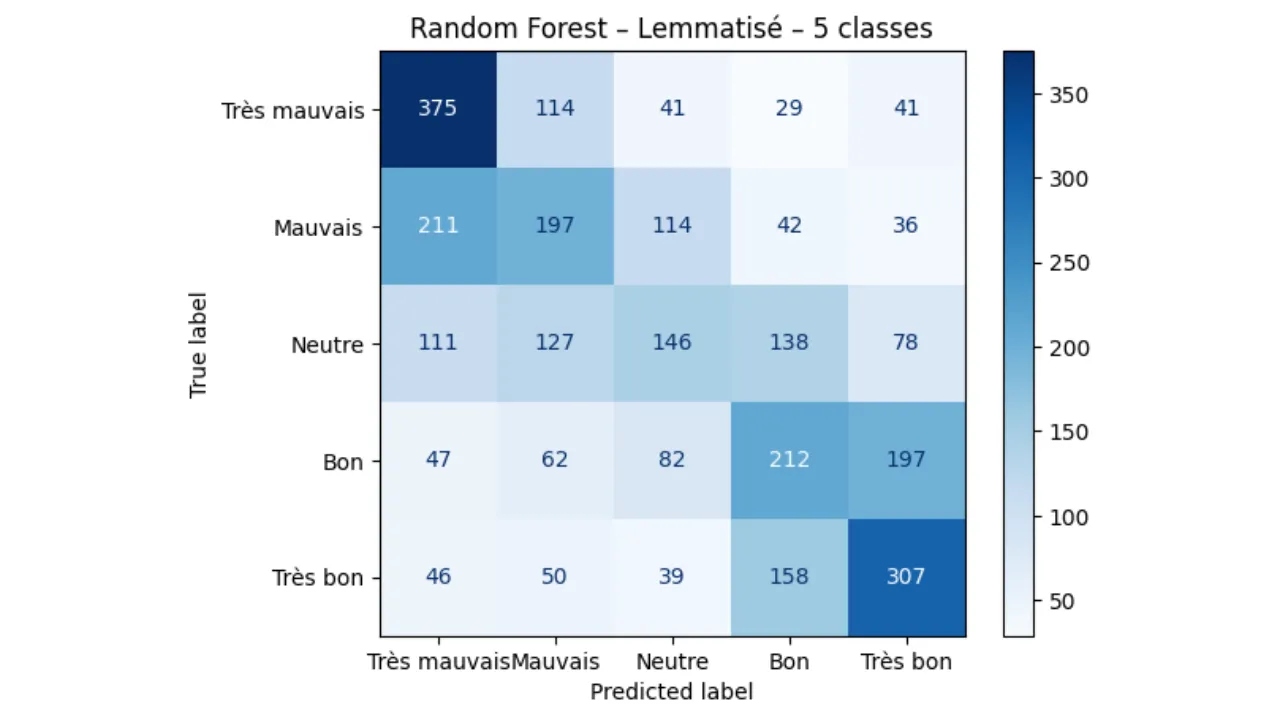
- Random Forest (Selected as the best performing model)
- Fine-tuning: Hyperparameter search using
GridSearchCVintegrated within Scikit-learn Pipelines. - Comparison: Bar charts comparing Macro F1-Scores to identify the optimal text/model configuration.
3. Optimization & Regression
- Linear Regression: Predicted exact scores (RMSE) based on textual indicators.
- Residual Analysis: Used scatter plots and histograms to analyze prediction errors (Actual vs. Predicted ratings).
- Performance: Evaluated via RMSE on test and validation sets to measure numerical model precision.
Results Visualization
To evaluate model performance, we generated:
- F1-Score: To measure the balance between precision and recall for each rating category.
- Confusion Matrices to analyze classification errors.
- Precision-Recall Curves to verify robustness against class imbalance.
- Residual Histograms to validate error distribution in regression.
- RMSE Comparison across different preprocessing methods (RAW vs. LEMMA).